

I Read Everything From OpenAI About Building Agents
So you don't have to.


One thing I learned from John Carmack is that “you should read the docs”:

Even in the era of StackOverflow or now with LLM assisted “learning”, if you seriously intend to use a tool, you’ll save time by reading the documentation directly.
(Personally, I take this to an extreme. When using Perplexity or Deep Research, I’ll jump straight to the Sources tab and just dive in. You don't have to do that but at least reading the most authoritative, high quality references about something can be very useful.)
On the topic of serious intent, if you’re not “seriously intending” to build agents, you haven't digested this newsletter enough.
Reading about tools to build agents seems particularly impactful. One thing crypto has taught me is that a healthy counter-reaction to an industry where concepts are described with vagueness, grandeur and too much vibes is to go low to the metal and understand exactly what is going on. I can attribute my involvement in crypto to my initial curiosity about EVM internals in 2018.
The agent space is suffering from some of the same problems vagueness problems.
So I decided it was time to “RTFM”.
I read the OpenAI API docs, how to develop agents with the API and other collections of best practices about developing agentic workflows.
This post will feature some of the key insights I stumbled upon in the process and distill them into a sequential process you can apply right now to build agents.
But first you have to believe something.
BUILDING AGENTS IS EASIER AND MORE VALUABLE THAN YOU THINK
For Founders, the dual-benefit of developing agents is that they push on your margin from every side.
On the cost end, they help automate and increase the reliability and quality of any process occurring in your company.
On the revenue end, they help develop your existing products faster, turn your services into products and produce a range of expansion opportunities.
I wrote about why we underestimate their potential in a previous post You Should Use the OpenAI SDK:
Agents are pure, liquid enterprise value yet we still underestimate them.
And they are easy to build:
There are simple No-Code tools as well as SDKs for building and composing agents;
With the help of AI-powered editors, you can effectively “vibe code” agents too.
The techniques described below will come in handy but they are by no means necessarily to develop agents that either substitute or deliver improved workflows.
Lets begin.
1. FIGURE OUT THE INTERFACE
Interface creativity is your job. Picking the right interface is potentially the highest order bit in developing agents.
Couple of considerations:
Chat is a safe/versatile default. An underrated way to develop a chat capability is to build a CLI. Claude Code is a good example of this:

Don't hesitate to use a human-in-the-loop. But it's worth thinking carefully when to do this. Compare how coding IDEs constantly hand back control before taking sensitive agents while research agents ask questions only up front. Chris Tate’s Bridged Prompting could probably be adapted here for more creative ways to ask for user input:

Maintain flexibility. An important facet of agents is that they may have useful sub-components that you may want to interact with directly. By using an interface that supports some level of prompting instead of hard-coding specific workflows you can allow for more creative uses of every part of an agent’s blueprint. Don't think of agentic programming as building a workflow and calling the LLM as an API call. Think of it as building a declarative web of agents and tools.
Get creative. Systems of record or other products may find better ways to embed agents than a conversational interface.

2. SET UP AN EVAL
One of the most insightful things I've read about engineering is the observe and measure part of Lambda's Engineering Philosophy.

The idea that engineering is only useful to the extent that it serves a singular metric probably pisses off a lot of Senior Engineers which is why I love it so much.
In the context of LLMs, the same rule applies - you need an eval. Think of it as a benchmark but applied specifically to your problem.
The hardest thing about coming up with an eval is deciding which problem to solve. For a multi-step workflow you may start with the end-to-end workflow in mind or focus on a narrow problem first.
When you figure that out, helpful tools already exist to make this easier like these pre-built evals:

3. USE TOOLS
If the most common problem is not using agents enough, the second most common is using LLMs too much in the agent.
If facing the choice of asking an LLM to do something vs. asking an LLM to write code to do something I’ll always prefer the latter.

When using the right libraries, you can turn all meaningful functions into tools and use them tactically either as functions or tools throughout your agent.
4. COMPOSE AGENTS CAREFULLY
While it’s tempting to have agents plan task execution, it introduces unnecessary variance in behavior compared to more straightforward orchestration patterns.
OpenAI recommend two: a manager and hand-off pattern.
Manager pattern
Decentralized/hand-off based pattern
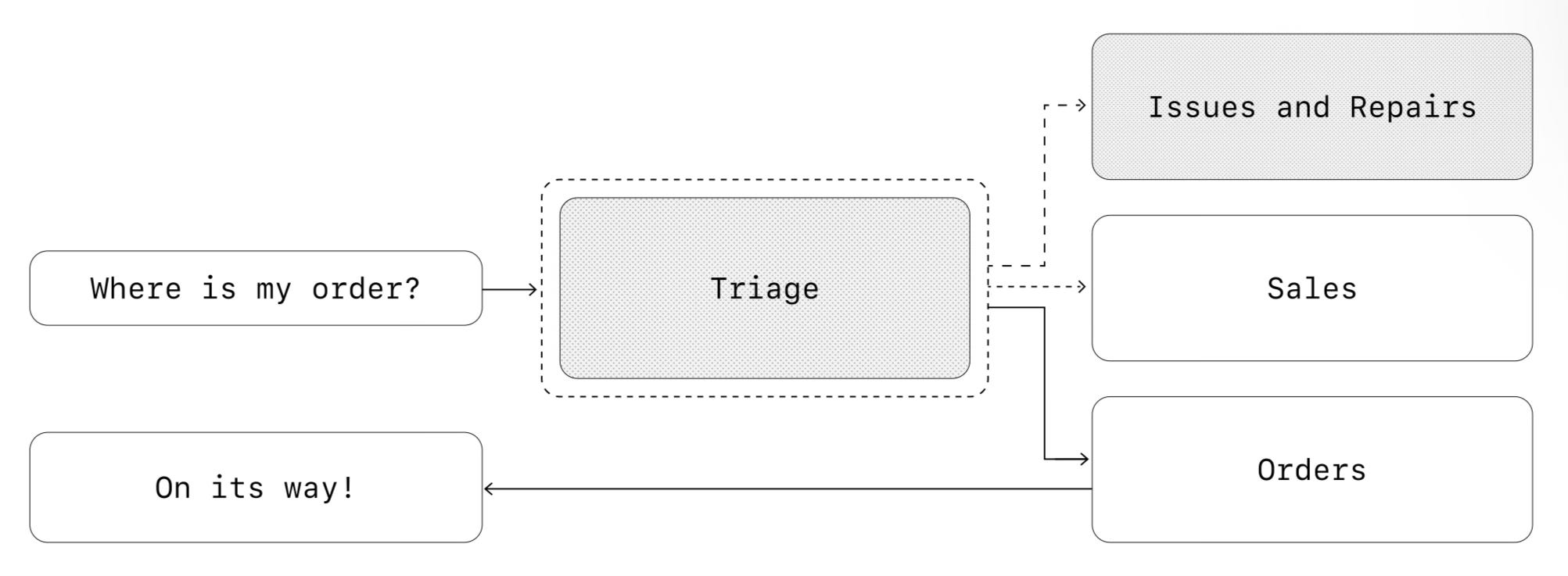
In short, “use task trees”:

5. OPTIMIZE
Once things are working and you hit the right accuracy, there are many more parts of the workflow you can optimize. This is why having an eval is helpful as you can use expected gains in accuracy or latency to prioritize exploration efforts.
In short, Release your Bottleneck.
Optimize the Model
OpenAI wrote a great guide on model selection:

Optimize the prompts.

Optimize the context.

By following a principled approach where you pick the right interface, define an eval and solve one performance bottleneck at a time, you can easily develop powerful agents.