

GPT-5 and the Great Slowdown
What we learned about LLMs this year and what it means going forward.

We are going through a re-calibration moment when it comes to LLMs.
They are not a scam but it doesn't feel like we are being swept up in the Singularity anymore.
It’s possible that we are in a much more nuanced (and interesting) timeline with slower AI development and this timeline changes how Founders should be building their business. Here are the signs I'm paying attention to.
First, there was a bizarre misalignment between how GPT-5 was promoted and how it performed. It failed to impress:

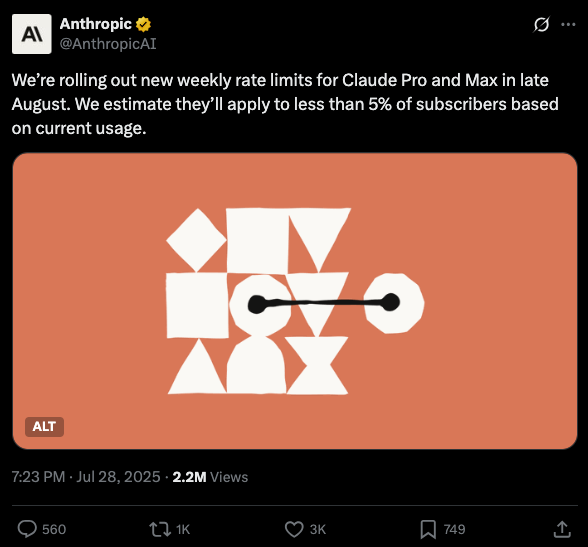
But users haven't just been disappointed with new models. Existing services like Replit, Cursor and now Claude Code introduced stricter limits on usage in a different form of regression. In many cases users that previously found the services useful find them less helpful with the readjusted pricing.
THE COMPUTE MULTI-BANDIT PROBLEM
One hypothesis is that OpenAI was (rationally) focused on coding performance. LLMs seem to have achieved the strongest product market fit in coding assistance. Personally, I find they are quite handy at finding sources during research runs too but people are more easily impressed with suddenly being able to create a video game than they are with a well-referenced report.
Reasoning models have unlocked performance on software but consume a lot of compute. Companies that create wrapper services (which also includes AI labs) have practical limitations on how they can allocate that compute.
Instead of paying money to acquire users outside the service, these services chose to over-allocate credits to subscribers to get embedded in workflows. When the subsidy is tweaked to manage utilization and profitability, outrage ensues.
As we reach decreasing returns to scale in model performance, the problem only gets worse.
For GPT-5, the idea of a unified model with built in routing on paper is friendly for non-power users with transactional tasks. Turns out even those users had attachments to particular model classes and their tonality (4o) while more sophisticated users missed the ability to control which model to invoke for each task.
SYCOPHANCY
Speaking of attachment, there are both academic and popular theories that LLMs are tuned to appease users:
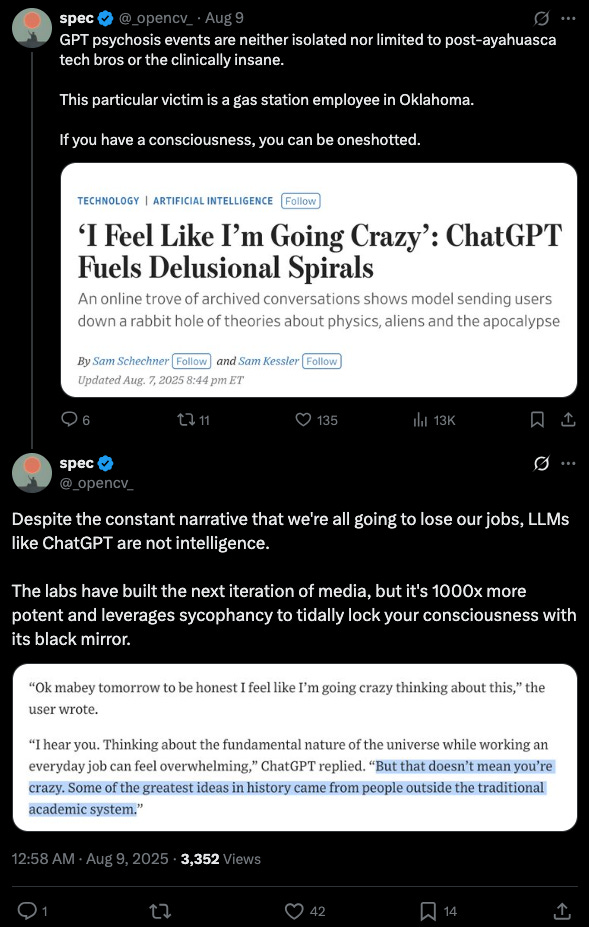
The hypothesis is that even at current performance levels most people cannot use LLMs profitably without long-term harm to their cognition.
The idea is best contextualized when looking at social media. A small number of social media users create the most valuable content and can benefit from the platform. For others, following friends leads to sadness and following the news leads to not pursuing their own ambitions. LLMs could have a similar impact.
In short, Facebook was the original drug, then came Netflix binging, long Covid and now LLMs?
WHAT THIS MEANS
I've touched on only some of the counter-narratives. If we entertain the possibility of model stagnation over the next 5-10 years, this postulates a different kind of start-up “meta”.
The “tools for thought” meta
Pre-LLMs, we glorified tools that supported our cognitive abilities or helped facilitate intellectual collaboration (Notion, Roam and Figma).
The meta was putting “tools for thought” on your X profile, creating a beautiful Electron app that took 50% of someone’s RAM and establishing a template directory so students could share their favorite ways of procastinating.
Of course, many of these tools embraced structured data formats and can support native AI integrations to ride the next meta also.

But that transition carries risks and I think Figma’s exit couldn't have been more perfectly timed.
Infinite interns meta
Assuming ongoing reduction of compute costs and fundamental increases in capex, we are in the “infinite interns” meta where you can't produce a masterpiece by chaining together low-skilled interns but you can automate an endless amount of tasks with a clear and achievable definition of done (like coding).
This explains the natural evolution of coding tools from the original Copilot (tab completion) to Cursor (assisted coding) to Claude Code (subagents, e.g., finite interns).
Scarce: intelligence, automation workflows.
Founders build: workflow agents.
Data absorption meta
Another possible pre-singularity meta is that LLMs will absorb all published data and become highly accurate at factual citation.
In this world, the bottleneck is the training data and anything from AI glasses to proprietary deals with enterprise companies to humanoid robots interacting with humans will be used to generate more of it.
Scarce: intelligence, data.
Founders build: startups with domain data loops.
Supercomputer meta
Another possibility is that while we see decreasing marginal returns from training data, we may see winner-takes-all returns in reasoning power and ability to process real-time data. In this meta, AI is able to absorb micro-signals better than humans or existing algorithms and comes to disrupt markets.
Results from individual model applications are recognized as limited while deep reasoning runs run by hedge funds, research labs, startups achieve super-human performance.
This approach, while still limited, would also come with the biggest disruption to labor markets.
Scarce: economic loops (e.g., hedge fund).
Founders build: research firms.
FINDING A PATH FORWARD
Ultimately, the aim of this post is not to make a negative statement about LLMs. It’s entirely possible that we could continue to discover better model architectures and find the next S-curve, LLMs are so recent that progress has been outstanding by any measure.
Instead, the point is to encourage Founders (especially “AI Founders”) to think about how different forms of underlying model stagnation could impact what they bet on.