

Synchronous vs. Asynchronous Proving
How the limitations of ZK coprocessors shape their use cases.

The world is catching up with the proving paradigm.
Two popular tools that amplify protocol development are zkVMs and coprocessors.
zkVMs often built in the form of rollups (like Starknet and Scroll) provide an execution environment for smart contracts that is natively provable.
Coprocessors, however, replace trusted onchain oracles, allowing outside provers to submit verifiable data onchain.
Why zkVMs
The benefit of zkVMs is that they have synchronous access to current onchain state in the host chain, allowing smart contracts to compute over it efficiently.
The convergence of block validation and proving is very elegant, effectively allowing L2s built on zkVMs to benefit from significant compute compression without loss of developer ergonomics.
To simplify – developers deploy and run simple smart contracts, provers prove transactions.
Why coprocessors
The benefit of coprocessors is that they have access to historical onchain state or current onchain state on any chain.
However, they do not maintain their own state.
A common application is to use them as a form of a “state oracle” (also called a storage proof).
This involves submitting a value that is computed as a function of historical blockchain state (for example, the airdrop eligibility score of an address based on their historic behavior).
They provide a powerful competitor to legacy oracle networks which have naturally relied on off-chain services:

Pragma are building the first oracle network that is built from the ground up with provability in mind.
Interplay
The natural question to ask is why can't we merge the two?
Ideally, our app wouldn't have to rely on 2 different networks of prover services.
In principle, the functionality of coprocessors could be entirely absorbed into zkVMs. In fact, I expect successful coprocessor companies to work on their own zkVMs.
However, their data requirements would impose an additional burden for provers.
This could hurt prover decentralization by increasing proving complexity (provers would have to have access to archive data across many chains).
Instead, we have to rely on using coprocessors asynchronously in zkVMs.
This could be seen as a lightweight form of recursive proving (where several larger proofs are aggregated into a composite proof).
Emergent ZK architectures
Traditional synchronicity
To understand how to combine the merits of zkVMs and coprocessors in smart contracts, we have to study the concept of synchronicity.
In traditional programming, asynchronous computing is known as more performant than synchronous computing.
Asynchronous in this context usually means allowing a piece of code to run on the best possible available computing resource.
Synchronous computing means that all pieces of code have to run in sequence, one after the other on the same computing resource.
The problem with synchronicity in a traditional computing context is that it is “blocking”.
If the first computation takes a long time, the rest of the compute chain cannot begin and is held up (blocked).
Blockchain synchronicity
In distributed state machines, we have the inverse preferences.
Synchronicity means that computations can exist in the same transaction. Block limits ensure that computations won't be blocking.
Asynchronicity means that computations have to occur over several transactions which by definition introduces an undesirable delay.
In fact, this means that asynchronous transactions are more likely to be “blocking” if there are issues with offchain relay or congestion on the destination chain.
So asynchronicity is rarely used to break up bigger computations, it’s usually incurred as a cost of doing things offchain or across multiple networks.
For example, bridge transactions are asynchronous, requiring a transaction to occur on both chains.
Oracle transactions are also asychronous. A common use case is VRF or verifiable random functions, which allows a smart contract to “request” a random value asynchronously and then receive it at a later block.
Coprocessors work very similarly to oracles.
A smart contract issues a query which then is resolved by the prover service, posting a proof onchain.
Limitations of asynchronous coprocessors
Protocol designs must accommodate asynchronicity.
For example, figuring out how much rewards each user should accumulate for a one-time reward based on their past behavior is achievable.
Using a custom formula for real-time reward accumulation is not possible. This is why protocols like Compound use clever techniques for reward accumulation that simply rely on current user balances.
Figuring out a starting auction price for an NFT based on its attributes is viable.
But creating a system that can price NFTs dynamically to support borrowing against them and just-in-time liquidations isn't.
Certainly not until aspects of coprocessors are embedded in zkVMs.
When to use each
Are you simply looking for efficient compute and the ergonomics of a programming language?
While Risc0's Bonsai coprocessor supports Rust and has many computational examples, the simpler route is to run your smart contract on a zkVM which will benefit from the same compute compression while retaining synchronicity.
Are you on a non-provable chain or need access to historic data?
Then you should be using a coprocessor.
Below are some examples from Axiom's presentation on possible coprocessor use cases:
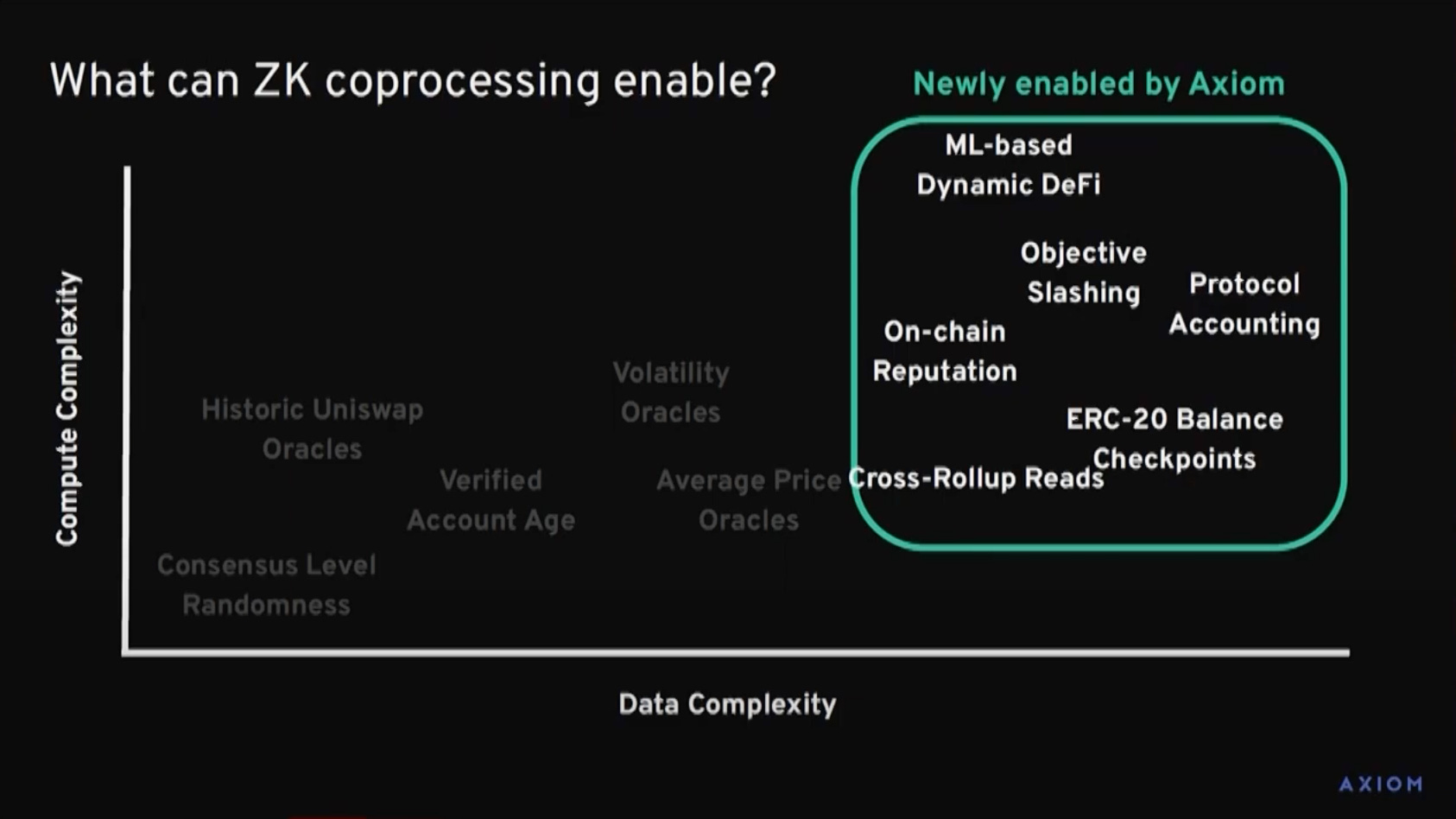
Watch the full talk: “Axiom: The first ZK coprocessor” here.
I do think coprocessors will find a plethora of applications.
In many use cases, for example objective function computation as described in a previous newsletter, asynchronicity is good enough.
The move away from trusted oracles is a welcome one by the developer community.
As with onchain rewards, I'm sure elegant designs will emerge that will mitigate the limits of asynchronicity.